Agile Services - Part 5: Team Processes

This is the fifth(!) post in the series about how to apply Agile methods to run services based on existing software.
The first post describing the problem at some length is here, but the TL;DR; is
I don't think there are great resources on how to apply agile methods to run and develop services based on existing (open source) software. We have struggled with it, and I try to write down practices that work for us, mostly taken from Scrum and SRE.
The second post discussed how the service lifecycle looks and when, what kind, and how much work we need to apply to the service.
The third post tried to classify that work that goes into the day-to-day administration of a production service.
The fourth post discussed teams vs. individual admins and some important aspects of a team.
Now, to the team processes. This post is what I originally wanted to write, but I wanted to give some background to this post, so I'm not just ranting to myself in a deep rabbit hole.
Some practices we have found useful,but they are not described in other frameworks. They may still be useful for others too, so I'll mark them with our practice in this blog.
Normal disclaimer: these are my own opinions based on my own experiences.
The Setup
So, after all those blogs, we now have gotten to a starting point where we have
- A team of full-time members
- with clear responsibilities for one (to simplify this blog) production service
- and constraints what they must adhere to
- but otherwise freedom to organize their work as efficiently as they can
- where their tasks include operations and development of the service
- and the team has a product owner, and a scrum master
If we can agree on these points, I think we have already come quite far.
Extra roles
Let's start by defining two extra roles. Both the roles are rotating ones, and held one week at a time. One of them is pretty standard.
Sheriff
In other places, this is often called "Operator on Duty" or similar. We call it Sheriff, because it's cooler, and we can wear a hat if we want. The Sheriff role is a rotating role, and each team member has it for one week at a time.
If we look at part three of these blogs, the purpose of the sheriff is to be the first line of defense against all the interruptions for the team. The Sheriff takes care of answering tickets, acting on alerts, and evaluating CVEs. This is basically the "unplanned" part of the work.
If there is too much work, the Sheriff does not need to handle everything by themselves, and e.g. in case of incidents, they are not allowed to handle them alone. The Sheriff can always call on the rest of the team for help, if there is too much work.
If it's a quiet week, maybe the Sheriff can work on some other tasks, but they are explicitly not expected to. Their responsibility is sheriffing.
Reviewer - our practice
For a long time we had problems how to make sure we put enough importance on task reviews. I assume you have also been in a situation where the "Review" column of your Kanban board is filling up. Even if the whole team agreed that task reviews are important, they seemed to be of secondary importance in practice. Good reviews take time, and familiarization with the task.
The thing that has worked best for us so far is to make sure it's somebody's responsibility. We have the reviewer role. That person's main responsibility is to review tasks. Again, they may have time to do other things (but, surprisingly, sometimes reviewing takes up most of that person), but they are not expected to. The reviewer role is also rotating, and held for one week at a time.
Having a assigned reviewer really keeps the work flowing, and help with a build-up of WIP.
Sprints
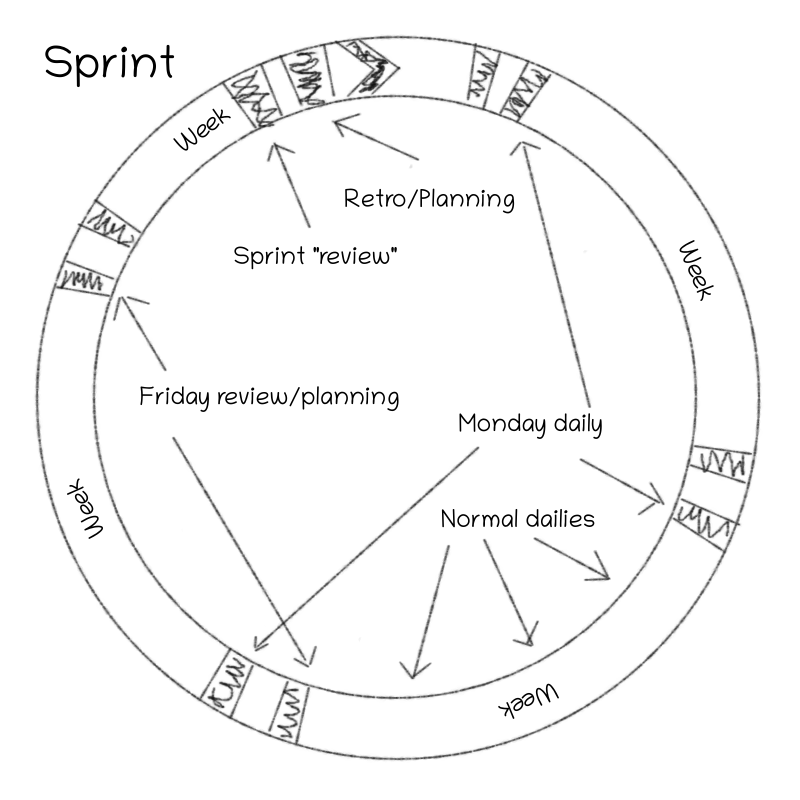
Scrum is quite strict on the processes you should run, and how you run them. I think it's good, as it's clear starting point on how to organize work. But let's tear them apart and make them work for us.
Scrum works a lot around a sprint, and what gets done in a sprint. I think the sprint is a good pacing of work, but let's throw out most of the hard requirements of a sprint.
Sprint length
There are some times very strict opinions how long sprints should be. Like either two or three weeks! Nothing else!
In our line of work, a lot of work is done on completely different time spans. I honestly don't care how long the sprints are. Currently we have a for example four week sprints in one team, and three week sprints in another. In general, I think we should keep sprints long enough so the sprint meeting cycle doesn't break up the work too much, and short enough so you don't end up with a too long of a backlog of things to discuss.
Retrospective
There is one meeting I'm saying you are not allowed to remove. It's the retrospective. The retrospective is the best invention in the history of job organization, especially if it's efficiently used.
We usually have quite long and involved retrospectives. For some teams, it could be too heavy, but tweak it to fit your needs. We go through how everybody is doing, is there anything that is making people annoyed, or something we're especially happy about.
During the sprint, we can also put topics for discussion on a wiki page and we go through them during the retrospective. These items are a rarely technical, it's more team and process introspection. Then we discuss these items. We are basically allowed change anything (meetings, schedules, practices, etc.) within our constraints, except removing the retrospective itself. For maybe 50% of the items people raise we find some improvements we can do.
Real examples we've discussed.
We have too many false negatives in our monitoring.
We're now flagging in our retro notes any checks that are alerting too much. Then in the retro we decide what to do with them.
We currently have a risk that in some corner cases when running devel code, it may affect a production server if we have switched server between environments.
Add a task to add safety checks for this case.
Can everybody put their picture in gitlab, so it's easier to see by glance who's working on a merge request
Yes
Shall we set up a central Ansible control node for the only way to run Ansible against our systems
May be a good idea, but we skipped it after making an estimate on the effort/reward ratio.
So the discussion points can be pretty much anything. The topics can also touch other parts of the organization, and they may be very valid, if harder to change.
The changes we do monthly may not be huge. But the changes really add up with time. Even better, as the service matures, and the team dynamic changes, we're almost automatically adjusting our work methods to adapt to the new situation.
Review (as in meeting)
Allegedly you should invite stakeholders to review meetings to present and discuss progress etc. etc. When we're running a service, this isn't really applicable on a sprint level. As you'll soon see, or work is on a different timeline, and for most of our work, it isn't easy to have opinions on it if you're external to the team.
In our review, we go through all completed tasks within the team. We also look at any customer tickets that our admins have flagged, as they want to share some information in the ticket. We have this meeting mostly so everybody has a good view on the state of the service.
Honestly, I won't blame you if you skip the review completely, if it doesn't bring you much benefit.
Planning
We have tried by-the-books Scrum planning with planning poker and everything. We were planning the tasks for a three week sprint at that point, and assume how many points we can complete. I almost shudder at those memories. In retrospect, there are several reasons that this is a poor idea.
First and foremost, if you look at the the work we do, we have a decent amount of unplanned work. The time this work takes up varies a lot. When planning a sprint we don't even have a decent idea about how much time we have for planned work. However, this is interestingly enough the smaller problem with planning a sprint.
When we run a production service, a lot of our changes touch many places around the organization. Let's say we order some hardware for our service, and it arrives. We need collaboration with many groups to get it racked and installed, verified, tested, etc. It sounds quite optimistic to plan around communication overheads and other teams' schedules, and still expecting to have everything ready in a three week sprint. A lot of our work - especially development work - in a production service is like this is not done on 3 week schedules. Some changes may be done in that time, others may be planned and developed over 6 months.
So locking sprint targets with a set of tasks that we ensure bring value by the end of the sprint, and expecting to reliably finish those tasks is unrealistic. Panicking over burn down charts or seeing if we're hitting our arbitrary "goals"doesn't help anybody.
What do we plan then? We generally look 6 months into the future, to see what it looks like, and we discuss prioritization of large items (we can call them Epics). We don't go to detailed planning of tasks in this meeting, as it's already a heavy day of meetings. We don't do sprint goals, we don't select tasks for the sprint, or anything like that.
But we do plan a bit. Later.
Daily
Our daily is - well I guess most of you have been to a daily. We try to sync up, and see if we have conflicts or if somebody is stuck. I find them quite useful if they are kept short and to the point.
However, when Roles for Scrum Teams discusses the team responsibilities, they say that "They have to perform the short Daily Sprint Meeting." Pfft. Why? If dailies don't work for you, do them 2 times a week. Or not at all. It really depends on your work and your team.
Monday daily - our practice
Now this is something we have done to help our team. Every Monday we have a longer daily. In addition to normal topics, we go through
- All ops tasks we have open on our kanban board. Just to make we don't have forgotten or stuck tasks.
- All internal and external pull request/merge requests, to see that they don't fall through the cracks.
- The organizational change calendar to see if there are changes that affect us.
- Scheduled meetings/events that affect the team this week.
- We assign a new sheriff and reviewer.
These takes an extra 30 min once a week, but the meeting has been useful for us.
Friday review/planning - our practice
This is something relatively new for us. We had a problem in reviewing tasks. Our larger development tasks generally have a lot of dependencies, and impact our production. Having one person working on the task and and then pushing the task to review, made the reviewer's life really difficult as they had very little context to that task.
Every Friday we take a deeper look at the development tasks. The person in working on the task presents it, their findings, design choices and their suggestions. As a team we discuss these, and if needed adjust the direction of the task. When we do this weekly with the team, it prevents people going down long rabbit holes with possibly wrong assumptions. It also makes reviewing the tasks much easier, as everybody has decent context on it.
We probably do more planning in this meeting than in our sprint planning meeting. This reduces the feedback loop time, and lets us gather knowledge to base our decisions on. This meeting has worked out really well for us.
Stakeholders? Where do they come in? - our practice
In our sprint cycle, we don't include stakeholders at all. But stakeholders are still kind of important, aren't they?
There are two main interactions with stakeholders. First, the Product Owner should actively discuss with stakeholders to sync the status of the service and the expectations from stakeholders. This includes being able to react and prioritize any sudden and unexpected requests.
But we also do have larger stakeholder meetings. Currently we do it approximately three times a year. This feels like a good cycle for us to communicate relevant developments of the service. Lately we have joined up with other services, so the stakeholder meeting is about a set of similar services syncing the developments and expectations with their stakeholders. This has been quite successful, and we're iterating on our approach all the time.
Recap
To sum up, we de-emphasize some meetings like review and planning, and add more meetings, like Monday scrum and Friday review. These meetings were discussed and added to our week by discussing how to solve issues in our retrospective meetings. So the team members actually requested more meetings! On the other hand, we're quite strict with our meetings. No laptops/phones during meetings (except remotes, but then only for the meeting), meetings start on time, and don't drag out unnecessarily.
Currently this meeting structure seems to work decently well for us, but it will undoubtedly change at some point when the work evolves.
Prioritizing Dev/Ops work
As per normal practice, a team should have a backlog. This is normal. How do we handle ops/dev priorities in the backlog?
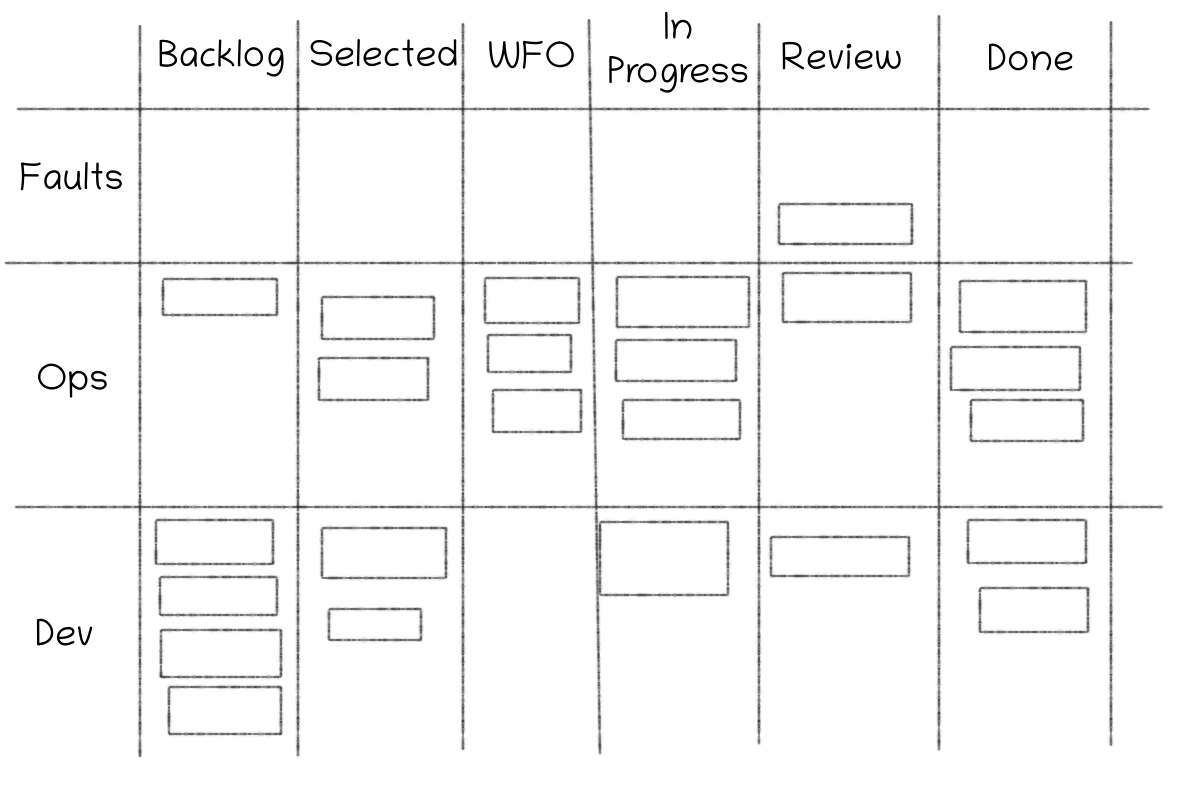
We have three different swimlanes (Jira term?) for our backlog. First we have faults. These are all-hands-on-deck incidents. These always take the priority and are the most important tasks. However, these don't get scheduled or prioritized, they get created when we have and incident.
Next we have ops tasks. When an admin needs to take a new task, ops tasks are always higher priority than dev tasks. So if we have an ops task in selected for development, the admin takes that. What makes a task an ops task? I think the third blog post post has a decent description of the characteristics of the tasks. Basically they need to handle a degraded or soon-to-be degraded state of the system.
We have become quite strict with creating and prioritizing ops tasks. As ops tasks were prioritized higher than other tasks, and we were quite liberal with creating ops tasks, we tended to get "important" development tasks in our ops swimlane. Now only the PO may move ops tasks from the backlog to selected for development, which has helped the issue.
Next we have a swimlane with development tasks. These are prioritized by the PO based on our planning meeting and stakeholder communications.
As a lot of our development tasks are larger, we basically prioritize what scrum would call epics. These may take a while to implement and consist of many individual sub-tasks. The main this is that we prioritize them as an epic and not as tasks. Usually we don't get any team or customer value from completing a single task, unless the whole epic is done.
Currently we have too much ops work, so prioritizing development isn't too hard, as there is a clear order of what we need to get done. With a bit more available development effort I'd like to try something like Weighted Shortest Job First in a bit more rigorous way than just off the cuff.
What if we can never do any development because we have too many ops tasks? I attended an SRE course, and that had an good term for this, Engineering Bankruptcy. If you're in this state, you probably need drastic changes. A rule of thumb for a good balance would be 50/50 ops/dev tasks, while actually managing to handle all the ops tasks.
WIP and work visibility
The next big thing when working on tasks is handling the work in progress.
The more things you do at once, the longer it takes to do them.
Managing WIP is in the core of many agile methodologies. For a good reason. A task is not useful before it's done. We try to put much effort into managing WIP and making sure we do our best to limit things in flight. This takes constant work, but it's worth it.
If you want to manage WIP, you also need to make sure that as much work as possible is visible. This means that there is a ticket about it. If a lot of shadow work is going on, it's hard to control WIP, as we don't know our WIP. Our goal is that all our work has a ticket assigned to it. Either it's a Jira ticket, or a customer ticket (these we handle outside Jira). My guess is that we currently catch 80% of the work, depending on how you count.
How can we manage our WIP? Let's say we have an admin who just put their only task into "review" (more on this soon), and now wonders what they should do. The first reaction is to take the next task in selected for development. This would increase our WIP. What can we do instead?
- If we have efficient reviews, the task is reviewed quickly and the admin can continue finishing the task, or fixing problems with it.
- Does the team have other WIP tasks, that are assigned to another admin who doesn't have time to finish them? Can the ownership of the tasks change?
- Does any other team member need help or a second pair of eyes for their ongoing task?
- Was there that mail/customer ticket/chat you could take care of now?
Now, if all none of the above yield any more work, we are in quite a good state. Then we can take a new ops or dev task into progress.
However, we never drag in new epics like this, starting a new epic is a conscious decision by the team. This is generally not a problem, as new epics should not be in selected for development.
The Infamous WFO
I'm sure most of you have a Waiting for Others column. It exists for tasks we can't forward ourselves, but we have to wait for some other parties to do something.
This is a necessary evil, and we can only try to make the best out of it. The WFO column basically always increases WIP, which isn't great.
The largest problem comes from WFO tasks hanging indefinitely in the column.Here our Monday dailies help, as we always go through these tasks and see if they can be kicked forward.
Task Reviews
To make the separation clear,this section talks about individual task reviews, not the review meeting.
Task Reviews is one of the things I we always must have (i.e. don't remove them in the retro meeting). We do extensive task reviews, and most tasks are put into the review column multiple times during their lifetime.
For us a task is reviewed e.g. when
- There is code to be reviewed and merged
- A second pair of eyes is needed for e.g. a proposed process for production change
- A review of some data which gets added to a system (e.g. hardware inventory) to validate the data quality
- The task implementer feels like the Definition of Done is met, and wants a final review to resolve the task
Having active reviews is an excellent way of building in quality. The most expensive thing is to half-ass a task and having to revisit the same problem multiple times after we have pushed it to production.
I think a telling point is that a majority of our tasks do not pass the first review, even though our admins know their task is going to be reviewed. If all these tasks went to production without review, we would build in a massive amount of technical debt into the service.
Final summary
So I've tried to describe a bit our process now, and how we work. This is not how we worked a year ago, and it won't be the way we work in a year. But most of the processes will remain the same.
If this was a long post, and you just scrolled to the end to see if there is anything interesting, at least read this.
- Have retrospectives. Don't be afraid to do changes to your process. Don't do things just because Scrum tells you to. But be honest and critical with your changes.
- Limit your WIP. It's hard but work on it.
- Review a lot and often.
I think I still have a few blog posts on this wider topic, so I expect there to be a part 6, at some point.
Geek. Product Owner @CSCfi
